

Cp/Cpkの計算方法
Cp、Cpkは工程能力を示す指数です。Cp、Cpkを理解するには、まずヒストグラムの内容を理解する必要があります。
ヒストグラムの描き方
実際にはソフトウェアが描画してくれるので、手作業でヒストグラムを描くことはありませんが、見方は知っておく必要があります。
まずはサンプルデータが必要なので、下図のように10個分のデータを用意します。右下は数値図と呼びます。誰でも馴染みのある折れ線グラフです。左下の表中の10個のデータがグラフに表示されています。



数値図
左のグラフは見慣れませんが、数値プロット図と言います。数値プロットとは、右の9.97~10.022の数値を順番に関係なく、ある階級で分けます。階級の数と、階級の幅の決め方はまた別の機会に説明しますが、統計分分析ソフトのqs-STATが自動で分けてくれます。今は下の表を見て、階級が5段階に分かれている事と、階級の幅(値域)が全部同じだという事だけ確認してください。
階級を分ける時、一番小さい数字から一番大きな数字がグラフの左から右へ順番に並ぶように分けます。グラフ中の「↓」1個がデータ1個に相当します。データが1個発生したが、「↓」を1個描画します。下の表の「階級の数」で階級が幾つに分かれているかが分かります。それぞれの階級に中にデータが何個あるかは「絶対度数」を見てください。

次に数値プロットの各階級にデータが何個あるかを棒グラフで表します。分かりやすくするため、各階級の棒グラフの上に、何個のデータがあるか数字を表示しています。

次に、このデータの分布傾向を表す曲線、分布曲線(分布モデルとも呼ぶ)を描画します。赤い釣り鐘型の曲線が分布曲線です。これはExcelでも書くことが出来ますので、時間のある方はネットで書き方を探してみてください。qs-STATは自動で描画してくれます。この左右対称の釣り鐘型の分布曲線を正規分布曲線と言います。
真ん中の青いXbar(Xの上に横棒が付いている)は平均値を示しています。
左右の青い破線(Xbar-3sと、Xbar+3sが示す青線)は、今後データが増えても大部分のデータはこの範囲に入るであろうという事を示しています。ちなみにXbar-3sが9.93663、Xbar+3sが10.06757です。
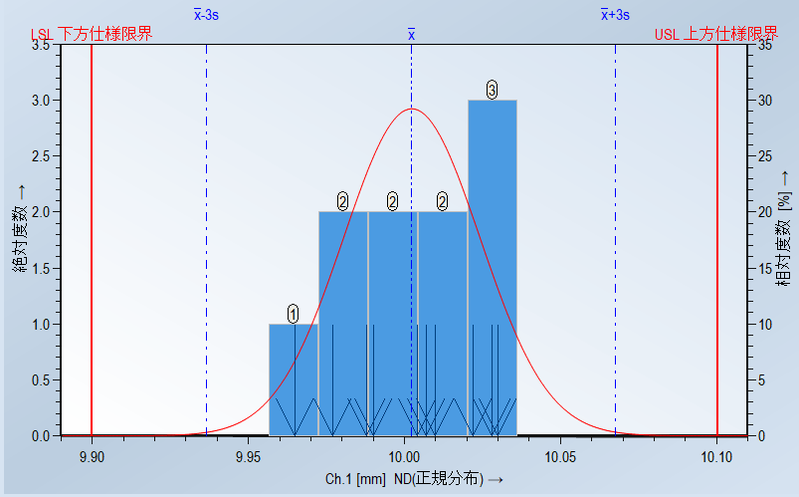
これでヒストグラムを描画できました。ヒストグラムはこの棒グラフと曲線がポイントです。分布曲線は、データが増えてくると、棒グラフの形が、この赤い線に沿った形になるという事を数学的に予測して書かれたものです。
今は10個しかデータが入っていないので、5つの棒が並んだ輪郭と、分布曲線の形が殆ど合っていませんが、データの数が多くなってくると、棒グラフの輪郭形状が徐々に分布曲線に近い形になってくるはずです。また、殆どのデータが、左右の青い破線の内側に入るはずです。
本当にそうなるでしょうか?
50個の場合

1,000個の場合

100個の場合

100,000個の場合

1000個辺りからかなり近い形になってきました。最初の10個のデータのバラつき具合から、この分布曲線に沿った割合で増えるという予想は正しかったようです。
また、最初にデータの大部分はは9.93663~10.06757の範囲になる(この範囲でバラつく)だろうと予想しました。100,000に増えた後はどうなっているでしょうか?同じ青の破線の数値を読み取ると、9.93978と10.06022となっています。最初に予測したバラつきの範囲にかなり近いですね。
この性質を使って、少ないデータから将来のデータの分布の幅や位置を予測する事ができます。
つまり、今10個のものを加工した時のバラつきから、100,000個加工した時のバラつきも予想できるという事です。
当然、加工した時のバラつきは小さい方が良いにきまっていますが、グラフを見た目だけでははっきりと良し悪しを判断できないので、数字で表す必要があります。このバラつきを計算するのがCpです。
Cp
Cpとはデータのバラつき度合を表すものです。
工程変動によるバラつきが小さければ工程能力が高く、大きければ低いという評価をします。バラつきの大きい、小さいを評価する基準は公差です。常に「公差と比較して」どうかという判断をします。
これをヒストグラムで表すと、良い状態が下図左、悪い状態下図右のようになります。
左右の赤いラインは上限公差、下限公差です。この公差の幅に対して分布がどの程度広がっているか(バラついているか)で良し悪しを判断します。
下図のヒストグラムから左側は、公差の中心付近にデータが固まって発生していますが、右側はバラつきが大きく、公差中心から、上限、下限の公差近傍まで幅広くデータが分布している事が分かります。


Cpはこのバラつきを定量的に表すもので、計算方法は下記のようになります。


計算はqs-STATに任せるので、上計算式を覚える必要はありませんが、式の意味するところは覚えておきましょう。上の式のσは標準偏差を表しています。工程能力評価を計算する上で基準となるのが、この標準偏差(σ)です。1つのσの幅がどのくらいかというのを上記のσ=・・・の式を使って計算します。
6σとは、σの値6つ分の分布幅を表しています。USL-LSLは公差を表します。
なぜ±3σなのか?
「なぜ6倍するのか?」という事の説明をします。
下図左の青点線-3σ(グラフ上はXbar-3sと表記されています)より小さい値が発生する確率は0.135%です。また、一番右青点線+3σ(Xbar-3s)より大きな値が発生する確率も0.135%です。確率的には-3σ(マイナス方向にσ3つ分)と+3σ(プラス方向にσ3つ分)の間に 100 -(0.135 × 2) = 99.73% のデータが存在する事になります。つまり±3σの外側のデータが発生する確率は3/1000以下という事になります。
確率的に3個は外れる可能性があるのですが、バラつきの範囲が公差よりも十分に小さければ、±3σを少々外れても公差外まで外れる可能性はさらに低いだろう、と考えられる訳です。
「何億個作っても1個も公差外は認められない!」という場合はどうすれば良いでしょうか?ちなみに±6σで計算すれば、±6σを外れる確率は10億分の2となり、限りなく公差外の発生はゼロに近くなります。しかしそのような工程を実現するのは殆どの場合、技術的に不可能で、経済合理性も低くなってしまう為、後の検査工程で不良を検出する等の方法で公差外品の流出を防ぎます。これらの観点から±3σは多くの工程で妥当な判断基準とみなされ、広く使われています。
上で説明した通り、Cpは「公差と比較してバラつき具合はどうか?」という評価をするので、ほぼ全ての分布幅(バラつき幅)をカバーしている範囲=6σと、公差とを比較します。公差を6σで割る事で、公差が6σ(バラつき)の何倍大きいかという事を調べます。
Cpは一般的に1.33以上で合格ラインと言われていますが、これはつまりCp=1.33というのは、公差がバラつきの1.33倍大きいと考えれば良い訳です。公差がバラつきより大きければ、大きいほど、6σから外れる可能性のある、3/1000個のデータも、公差を外れる可能性はより低くなるという訳です。
今回は±3σで説明しましたが、±2σで計算する事も、もちろん可能です。若干の公差外品が認められる場合や、その後の検査工程で簡単に公差外を検出できる場合、公差を緩くして加工し易くしておき、その後の検査で公差外品を除外する方が経済合理性高い場合もあります。(材料はロスしますが・・)作る側と作ったモノを受け取る側が双方合意できる基準であれば、どのような基準でも良いのです。重要なのは「評価基準が定量的に決まっている事」です。

Cpk
Cpは分布の範囲(品質のバラつき)を定量化したものですが、実はこの評価だけでは十分ではありません。理由は下の3つのヒストグラムを見れば一目瞭然です。下の3つのヒストグラムから計算されるCpはいずれも6.0前後(バラつきは公差の1/6)で、バラつきは非常に少ないと言えます。しかしこれらの品質評価は全部同じで良いでしょうか?
ヒストグラムを見ただけでも、両サイド2つのパターンはいずれもデータの大部分が公差に近寄りすぎているので、真ん中のパターンよりも悪いと予想できます。



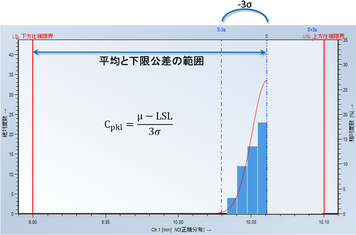
Cpkを使えば、上記3パターンの良い、悪いを定量的に評価する事が出来ます。Cpはバラつきを定量的に表す指標ですが、Cpkは規格値(設計値)との乖離を評価します。例えば右のヒストグラムを見ると上限規格値10.1に対し、バラつきの平均が10.08近傍となっています。バラつきは少ないのですが、10mmを狙って加工しているのに、殆どの部品が10.08mm前後で仕上がっているという事になります。
Cpkの計算式は下記です。各記号についてはCpの解説を参照してください。

この式もqs-STATが自動で計算してくれますので、覚える必要はありませんが、Cp同様、式の意味は理解しておく必要があります。下図の例題を使って説明します。ちなみに、この時のCpは3.21です。
バラつきは十分に小さいですが、上限公差にかなり分布が偏っています。

Cpkの計算式が表しているものを図で表すと下図のようになります。
Cpは公差全体とバラつき範囲の比較ですが、Cpkはバラつきの平均から右と、左を分けて評価します。評価に使うバラつきの範囲を半分にするので、σも6個ではなく、半分の3個(3σ)にします。CpklとCpkuをそれぞれ計算し、このうち小さい方をCpkとします。
式だけ覚えると、大きい方と小さい方のどちらを使うか忘れてしまいそうですが、ヒストグラムを見れば上限、下限のどちらが公差から外れやすいか(どちらを管理しておく必要があるか)一目瞭然です。よって下図の例の場合、バラつきの平均から上限公差までの範囲の方が狭い為、CpkuをCpkの値として採用します。

Cpがバラつきの範囲が広いか、狭いかだけを問題としてる一方、Cpkはヒストグラム中のバラつきの「位置」も考慮します。厳密にいえば、バラつきの平均値の位置です。すなわち「10mmで設計したものが10mmでできているか?」という、一般的に「絶対精度」と呼ばれるものも評価に含まれるという事になります。
勘の良い方は既に気づかれているかもしれませんが、正規分布において、公差の中心とバラつきの中心が完全に一致している場合はCp=Cpkl=Cpku=Cpkとなります。(比率が全て同じになるので)
下図の例はシミュレータを使って、全て1:3.32の比率となるようヒストグラムを作りました。

片側公差
片側公差(USLとLSLのどちらか一方しか無い)の場合はCpの計算ができません。このような場合上下どちらかの公差があれば計算できるCpkを使えば工程能力を評価できます。
「両側公差は、Cp、片側公差はCpkで評価する」と聞かれた方もいるかもしれませんが、「片側公差はCpkでしか評価できない。」が正解です。また両側公差もCpの評価だけでは不十分である事はこれまでの説明で明らかではないでしょうか。ものつくりの品質評価にはCpkを使ってください。
式を覚えても使えない!?
上の方の解説では、Cpも、Cpkも、それらの意味するところが分かれば計算式を覚える必要はないと書きました。
「式さえ分かれば、分布や標準偏差の計算もExceで出来るし、高価な統計分析ソフトなんて必要ない。」と思われるかもしれません。しかし実はここで紹介した計算式は、実際の工程能力評価に、そのままでは使えない事が多いのです。
実際の工程データは長期間記録していくと、教科書のように綺麗な正規分布になる事は殆どありません。実際の工程では、工具が摩耗したり、作業者が変わったり、材料のロットが変わったりと、時間経過による変動要因が数多く存在します。
他にも、平面度、表面粗さ、真円度は基本的に0以下にはなりません。これらのデータも通常正規分布にはりません。正規分布でなければ、σを計算したところで、1σ=68.27%にはならないので工程能力の計算には使えません。つまりσを使ったCp、Cpkも正しく計算できない事になります。
ではどうすれば計算できるでしょうか?
↓